
CARP Core is an infrastructure-agnostic, multiplatform, open-source software framework to help develop distributed data collection applications and infrastructure for use in research studies.
Infrastructure agnostic
CARP Core provides no integrations with specific devices, sensor technologies, databases, or user interface frameworks, i.e., infrastructure. Instead, it offers basic abstractions to implement such integrations yourself.
CARP Core is a software framework to help developers build research platforms to run studies involving distributed data collection. It provides modules to define, deploy, and monitor research studies, and to collect data from multiple devices at multiple locations.
From the CARP Core Framework README.
This is the result of adopting domain-driven design: CARP Core contains domain logic in the form of domain models which can be interacted with through application services. Dependencies on concrete infrastructure are injected into the application services defined in CARP Core. This is also known as onion architecture. As such, CARP Core is an extendable, lightweight, framework which defines and implements an open standard for distributed data collection.
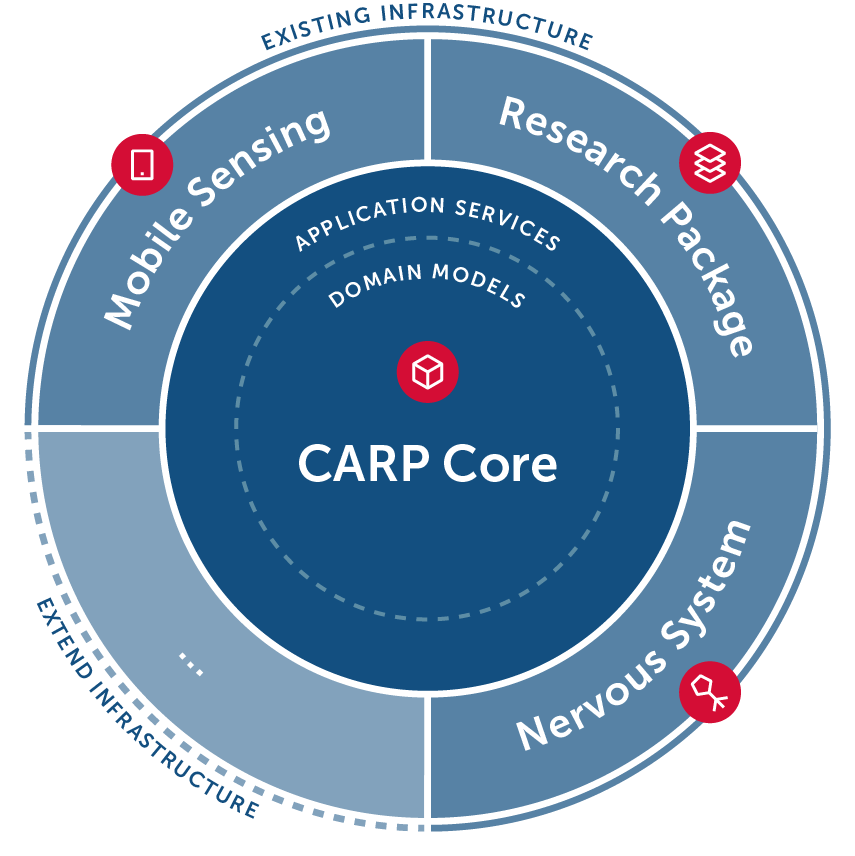
The entire CARP platform builds on top of CARP Core. You can add new integrations to the CARP platform, hosted by CACHET, by building on top of CARP Core. Or, you can choose to build your own infrastructure by implementing and hosting the necessary subsystems as defined in CARP Core.
Currently, the CARP core domain models are used in the following components:
- CARP Mobile Sensing enables the collection of sensor data on smartphones.
- CARP Web Services is a cloud backend for managing studies, participants, and data.
Multiplatform
CARP Core is implemented using Kotlin, which can target multiple platforms. We currently target Java (JVM) and JavaScript (with matching TypeScript declarations). Libraries are published to:
- Maven for Kotlin and Java.
- npm for JavaScript and TypeScript (still to be released).
Distributed data collection
CARP Core provides the basic building blocks to implement applications for any internet-connected device, such as smartphones, desktop computers, and smart speakers, to collect data from internal and external sensors and request data input from participants (e.g., surveys and cognitive tests). The data to collect is determined by a formalized study protocol defined using CARP Core and can be distributed to participating devices using a cloud backend which subsequently receives the data.
This functionality is provided across several subsystems:
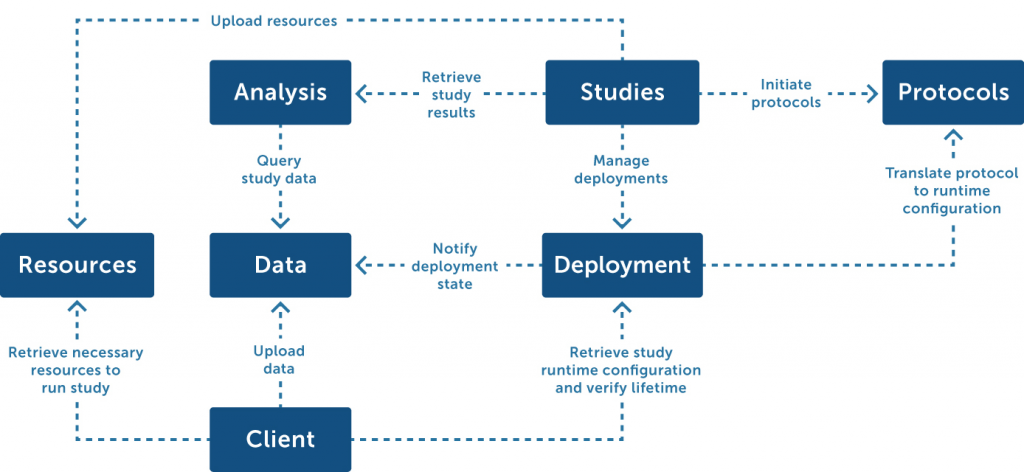
- Protocols: Implements open standards which can describe a study protocol—how a study should be run. Essentially, this subsystem has no technical dependencies on any particular sensor technology or application as it merely describes why, when, and what data should be collected.
- Studies: Supports management of research studies, including the recruitment of participants and assigning metadata (e.g., contact information). This subsystem maps pseudonymized data (managed by the ‘deployment’ subsystem) to actual participants.
- Deployment: Maps the information specified in a study protocol to runtime configurations used by the ‘clients’ subsystem to run the protocol on concrete devices (e.g., a smartphone) and allow researchers to monitor their state. To start collecting data, participants need to be invited, devices need to be registered, and consent needs to be given to collect the requested data.
- Client: The runtime that performs the actual data collection on a device (e.g., desktop computer or smartphone). This subsystem contains reusable components that understand the runtime configuration derived from a study protocol by the ‘deployment’ subsystem. Integrations with sensors are loaded through a ‘device data collector’ plug-in system to decouple sensing—not part of CARP Core—from sensing logic.
- Resources: Contains a simple file store for resources (such as images, videos, and text documents) that can be referenced from within study protocols to be used during a study.
- Data: Contains all pseudonymized data. In combination with the original study protocol, the full provenance of the data (when/why it was collected) is known.
- Analysis: An analysis subsystem sits in between the data store and the ‘studies’ subsystem, enabling common data analytics but also offering anonymity-preserving features such as k-anonymity.
Contributors

CARP Core is the result of a collaboration between iMotions and the Copenhagen Center for Health Technology (CACHET). Both use CARP Core to implement their respective research platforms: the iMotions Mobile Research Platform and the Copenhagen Research Platform (CARP). CARP Core is now maintained fully by DTU in an open-source manner in collaboration with other research partners.
CARP Core is available as open source on GitHub under an MIT Licence.